
Z Potentials | Inside Kepler AI: From GRAIL & Databricks to Securing Their First Biotech Client in Just One Week with AI Agents
Z Potentials invited Ashton Teng and Quinn Leng, co-founders of Kepler AI, to give a talk.


In the vast laboratory of life sciences, a torrent of data is rushing in at a pace never seen before. The cost of gene sequencing has plummeted 180,000-fold in just two decades—outstripping Moore’s Law—while the volume of data has exploded exponentially by more than a trillion times. Yet scientists remain stuck in the same old work paradigm: manually sifting through endless papers, going back and forth across departments to clarify needs, and waiting weeks or even months for analysis results. Out of Silicon Valley, Ashton Teng and Quinn Leng co-founded Kepler with the ambition to reimagine the foundations of scientific workflows using AI Agents. “What we’re building is a form of human-AI interaction that science has simply never seen before,” they explain.
Their partnership began with a shared curiosity about AI. Three years ago, Quinn was studying the “hallucination” problem in large language models and, for a short while, experimented with using AI for dream interpretation and tarot. Through a friend’s introduction, he met Ashton, who was equally obsessed with frontier technologies. At first, they were just two friends skiing, diving, and chatting about life. Over time, their conversations sharpened around the big questions of entrepreneurship: how to start from zero, and what actually counts as valuable. By last year, both decided—almost simultaneously—to quit their jobs and take the leap. “It’s rare to have someone you trust who’s ready at the exact same time,” Ashton recalls. From that friendship, Kepler emerged as a proving ground for AI in science.
Kepler’s entry point is life sciences. “In biology, data analysis capabilities are far behind those of the tech industry,” Ashton notes bluntly. Trained in neuroscience before moving into bioinformatics, he spent years at technology-driven biotech companies such as GRAIL, Foresite Labs, and Xaira Therapeutics. He witnessed firsthand the role of technology in advancing life sciences—and also its shortcomings. “After an experiment is done, scientists often wait days or even weeks to get their bioinformatics results. That slows the entire cycle of scientific iteration dramatically.”
Kepler’s mission is to serve as the “central nervous system” of research organizations. As Ashton explains, it can help scientists search literature and generate experimental ideas, but it goes further: connecting data pipelines, analyzing biological data in context with experimental metadata, linking results with an organization’s knowledge base, supporting conclusions, generating reports, and even proposing the next research question. In other words, Kepler isn’t just a tool—it’s more like an end-to-end scientist. And it can go beyond what traditional methods make possible: launching hundreds of questions in parallel and engaging with data at scale, enabling faster and broader exploration of potential discoveries.
Despite being surrounded by giants like OpenAI and other general-purpose model providers, Kepler projects a strong sense of confidence. Ashton puts it bluntly: “General platforms can’t solve the ‘last mile’ problem—they’re not going to dive into an enterprise and integrate with the specific workflows.” That conviction was quickly validated by the market: within its very first week, Kepler landed its first biotech client, underscoring the sector’s urgent demand for specialized AI solutions.
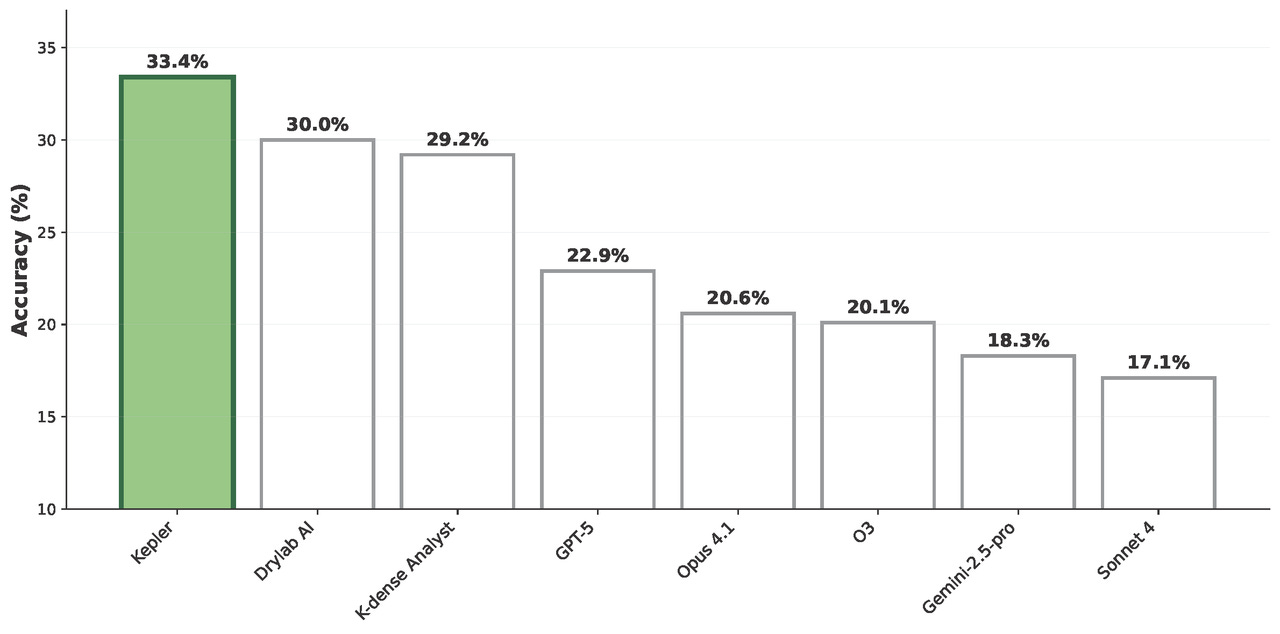
This focus on deep specialization has also been borne out in hard numbers. By tightly integrating domain-specific tools and data sources with highly optimized reasoning and experimental workflow planning, Kepler outperformed every general and industry AI agent in the authoritative bioinformatics benchmark Bixbench (https://arxiv.org/abs/2503.00096). With an accuracy rate of 33.4%, it surpassed models such as GPT-5, Claude-opus-4.1, K-dense Analyst, and Drylab—demonstrating the strength of its vertical technical moat.
A deeper shift is underway in the industry. Ashton and Quinn point out that AI transformation has now become a key measure of competitiveness for pharmaceutical companies. “In the past, big pharma had little interest in startups, but now the window has opened.” Competition in the sector is intensifying, and the ability to achieve AI transformation quickly will directly determine an organization’s strength. Yet despite being able to hire talent, large pharma companies are not AI-native; their in-house tools are often constrained by speed and generality, serving only piecemeal needs and lacking the reliability and scalability of professional products. This structural shortfall has created unprecedented opportunities: leading pharma companies are now actively evaluating and partnering with AI startups—something almost unimaginable just a few years ago. For Kepler, this represents not only a new opportunity created by technology, but also a sign that the digital transformation of life sciences has entered a deeper phase.
Kepler’s ambition goes well beyond biology. “There’s no ceiling on scientific exploration,” Ashton says. “Materials, climate, agriculture—anywhere R&D is needed, AI will be essential.” Quinn, speaking with an engineer’s precision, frames the challenge ahead: “We’re facing some of the most complex problems in the industry—working with multi-modal datasets on the order of hundreds of gigabytes, designing AI-driven decision processes that can actually be verified. None of this has precedent.”
In this scientific frontier, Kepler is running at Silicon Valley speed through uncharted territory. They also use their culture to filter partners: self-drive, curiosity, customer obsession, and a native embrace of AI tools. As Ashton puts it: “We’re not experts in AI for science—we’re active participants. Every day we uncover new needs, and that process itself is fascinating.”
This edition of the Z Potentials interview series features Kepler co-founders Ashton Teng and Quinn Leng, who joined us to share their entrepreneurial reflections. Enjoy.
No company has ever built a product for true “scientist–AI Agent interaction.” Questions arise that have never been answered before: How precise should citation be? Deep Research can target a specific webpage, but we need to reference a particular experiment—or even a single row of data in a database. How should that workflow be designed? Which steps can the Agent carry out autonomously, and which require human confirmation? These are entirely new interaction models that must be reimagined from scratch.
Pharma companies had already considered the need for a natural-language interface to interact with data, but building it in-house proved too difficult since software development wasn’t their core. Outsourcing was another option, but results fell short. Kepler arrived at the right moment: they had the data, Kepler brought the specialized product capabilities.
Today, the pace of competition in pharma is brutal. AI transformation has become a critical benchmark. While big pharma can hire talent, cultural DNA matters—without AI at the core, internal tools are slow, limited, and built only for internal use. They lack the reliability and universality of a product designed to serve many companies.
This is why Kepler does not see OpenAI or Anthropic as immediate threats. “They’re building general-purpose tools,” the founders explain, “but we optimize models for the specific needs of biology.” General AI providers face a “last mile” problem: they won’t embed themselves inside enterprises to integrate tightly with workflows.
Traditional software vendors aren’t well-positioned either—their innovation cycles can’t keep up with the pace of AI, and they lack true AI-native products. That gap has opened a rare window: big pharma, once reluctant to engage with startups, is now open to partnerships with early-stage AI companies. Previously, AI firms would cut their teeth with smaller biotech clients before scaling up to larger players; today, many top pharma companies are proactively evaluating AI startups from the outset.
Kepler’s long-term vision is to become the “central nervous system” of every research organization. While their current focus is research—especially AI Agents for scientific tasks—their technology can extend across domains: materials science, climate research, agriculture, and more. All these fields share similar R&D demands.
The founders are quick to add that this is not a winner-takes-all market. Scientific research is vast, unlike verticals such as sales automation where ceilings are clearly defined. Scientific exploration is limitless, and AI’s role within it has no fixed boundary. There’s plenty of room for multiple companies to thrive.
01 Pioneering TechBio: At the Crossroads of Scientific Dreams and Business Vision
ZP: Could you both share the key experiences or projects early in your careers that shaped your determination to start a company today?
Ashton Teng: I grew up in Beijing and Canada, and from a young age I wanted to be a scientist. So when I went to college at Berkeley, I chose neuroscience and computer science. Initially, I planned to pursue a PhD in neuroscience, but in my senior year I happened to take extra courses in genetics and molecular biology. I developed a strong interest in the field just as gene data was beginning to grow exponentially, creating new opportunities for applications. That led me to Stanford, where I did a master’s in informatics.
Since high school, I had also been interested in history, economics, and business, often reading books and news in those areas. During college, I wanted to combine my interest in science with my interest in business, so I joined some entrepreneurship clubs. The one that influenced me the most was ACE, a Chinese entrepreneurs’ association at Berkeley. Being immersed in the Silicon Valley startup culture there left a lasting impression on me, and I constantly thought about starting my own company. Still, after graduation I decided to gain industry experience first.
I went on to work at several TechBio companies—GRAIL, Foresite Labs, and Xaira Therapeutics. Because I always wanted to build something myself, after my internship at Microsoft as an undergrad, I never considered working at big companies again. At these startups, I was constantly exploring frontier trends: at GRAIL, I worked on cancer diagnostics; later, I moved into AI-driven drug development. What they all had in common was a reliance on massive datasets. I was always searching for entrepreneurial opportunities, often leaving once I felt I had learned enough, even walking away from unvested equity. For me, growth mattered more than anything, and starting a company felt like the best way to keep growing and make an impact.
At the time, cancer diagnostics and AI-driven drug discovery weren’t labeled as “AI for Science.” The focus was on solving very specific problems. Cancer diagnostics, for instance, was purely about diagnosis—nobody was saying AI could reshape the daily workflows of scientists. Applications were point-to-point. Even the idea of biological foundation models only gained traction in the past few years.
So the last wave of “AI for Science” was really more about machine learning applications in healthcare. That wave did produce some successes—GRAIL’s product, for example, was solid—but it wasn’t anything like the transformative impact people now expect from large models. Earlier applications were much narrower. I only heard the phrase “AI for Science” for the first time at the start of this year.
Quinn Leng: Ashton mentioned wanting to be a scientist as a kid. For me, I actually wanted to be an inventor—I thought inventors were cool because in cartoons they could create amazing things instantly.
I was always curious about how things worked. In second grade, I completely took apart my family’s TV, studied every piece, and put it back together. I just wanted to see what it looked like inside and how it all ran. That curiosity carried into everything I tinkered with later.
At Huazhong University of Science and Technology, I joined the Lianchuang team, where we experimented with mobile apps, blockchain, AI, and distributed systems. I even co-founded a startup with some friends; three of them later became co-founders of Manas. It made me realize that technology drives the world in two ways: through hardcore deep tech, and through finding ways to put that tech into users’ hands.
Later I went to Carnegie Mellon for a master’s, studying distributed systems and concurrency, and working on fun side projects—like using wearable glasses to guide remote emergency care. After graduation, I joined Databricks, leading the compute and storage team. I experienced the company’s growth from 100 to 10,000 employees, learning firsthand about scaling challenges, technical bottlenecks, and how to lead teams and build culture.
Over the past two years, I’ve personally felt how AI has touched almost every part of life—writing, chatting, programming. This is a unique moment: AI is directly permeating daily life in a way it never has before. As Ashton said, machine learning used to tackle narrow problems; today, AI is capable of connecting everything. That shift will bring not only technical change but also cultural and organizational change. It feels like the right time to build an AI-native company.
I’ve always been passionate about pushing technology forward and applying deep tech to valuable real-world contexts—whether in enterprises or science. So I was eager to start a deep tech company in the scientific domain, and eventually Ashton and I crossed paths.
ZP: How did the two of you first meet, and what led you to decide to start a company together?
Quinn Leng: We’ve known each other for nearly three years. Around the time ChatGPT was released, I was studying language models and ran into the big problem of hallucination—models making things up. That led to research questions about how to mitigate it, but I also wondered whether this property could be useful in some contexts—like entertainment, dream interpretation, or even tarot.
At the time, I co-founded a side company called Dreamore AI, where I was part-time CTO and led product development. It wasn’t my main passion, but it was interesting. Through my co-founder Coco, I met Ashton and discovered a community of Chinese entrepreneurs in Silicon Valley who were fascinated by these frontiers too.
Initially, it was just friendship—we skied, dived, and hung out, talking about life rather than work. Over time, we realized we had strong alignment in our views on entrepreneurship: how to build a company from zero, what counts as real value, how to approach a problem from the ground up. We had both spent years in the industry and had similar instincts about how to enter a space. Eventually, we decided to explore specific directions together.
Last year I was preparing to quit and start something new. The timing felt right, and as I discussed it with friends, I realized Ashton was thinking the same.
Ashton Teng: My New Year’s resolution was to start a company, and around his birthday Quinn had the same idea. It’s rare to find someone you trust who’s ready to take the leap at the same time. So we first committed to “starting something together,” and only later decided what exactly that would be.
ZP: When recruiting your early employees, beyond technical ability, what qualities matter most to you?
Ashton Teng: We’ve thought a lot about this and distilled it into four qualities. First is self-motivation. That means taking full end-to-end ownership of a project and having the responsibility to see it through. AI-native companies tend to be lean, so everyone needs to own more, often driving things solo. Responsibility and ownership are critical.
Second, after years in science-related fields, we’ve learned that at any given time we probably only understand 10–20% of the picture. Everything we discuss today is just our current best understanding. Like scientists, we must gather data, test hypotheses, and adjust accordingly. We don’t claim to be “AI for Science” experts—we’re active participants, discovering new user needs every day. That process is deeply engaging.
Quinn Leng: I’d sum it up as four traits. First, self-motivation—taking full ownership. Second, curiosity—essential for deep tech and interdisciplinary science. Third, customer obsession—iterating from the customer’s perspective, even embedding ourselves in their environment to understand problems firsthand. And fourth, being AI-native—embracing and deeply collaborating with AI tools to get things done.
ZP: Quinn, you’ve said life sciences is a “technologically underserved” industry. When you talk with pharmaceutical companies that make billions annually, what’s the most primitive data practice that has surprised you?
Ashton Teng: Life sciences at its core is about discovering more about nature. Physics and chemistry are also natural sciences, but biology is like a higher abstraction layer built on top of them. Biology’s defining feature is its messiness—it’s the result of evolution, not design. Unlike a computer system, it wasn’t engineered; it emerged through mutations and randomness, making it inherently complex.
From organs and tissues to cells and proteins, everything exists within extremely complex systems. That’s why life sciences fascinate me—because of that very chaos.
Early biological discoveries often came through trial and error. Penicillin, for instance, was discovered by accident. But the “low-hanging fruit” is long gone, and many diseases remain unsolved, with new ones constantly emerging.
TechBio is not about trial and error—it’s about systematizing discovery. In the past two decades, the field has shifted toward data-driven science. Breakthroughs in sequencing have let us read DNA at scale. In 2000, sequencing a human genome cost $100 million; now it’s under $500. Beyond DNA, we can sequence RNA and even single-cell RNA, and technologies like CRISPR allow us to edit cells and observe outcomes. In essence, technology is turning biology into a data problem, which is why many biotech companies now describe themselves as “data-generation companies.”
But that creates pain points. On one hand, there’s still vast unknowns, and data is being generated at an unprecedented pace and scale. On the other hand, analysis capabilities and software tools lag far behind those in the tech industry. Data processing and analysis have become bottlenecks.
That’s where bioinformatics comes in—a field combining biology, computer science, and statistics. Within companies, a new role emerged specifically to analyze these datasets. But bioinformatics talent is scarce. A small biotech may have scientists producing lots of data, but perhaps only one bioinformatician to analyze it.
This creates huge communication costs. Experimental scientists need to communicate their designs clearly to bioinformaticians for proper analysis. More often, experiments are completed and scientists must then wait days or even weeks for results. That slows scientific iteration dramatically. It’s one of the biggest pain points we focus on.
ZP: Bioinformaticians need rare hybrid skills. Without Kepler, how much time and cost would a top biotech company typically spend on a core analysis task?
Quinn Leng: Traditional internet companies split roles into data scientists and data engineers, and the definitions have been clear for years. Hiring is relatively straightforward. Their systems—data logging, collection pipelines, service frameworks—are already standardized, so candidates only need the matching skill set.
In biology, however, bioinformaticians need technical skills and biological knowledge. Salaries are actually lower than in top tech companies, but the demands are higher. As a result, the industry faces chronic talent shortages.
Ashton Teng: My own role in the industry was closer to a bioinformatics engineer. A bioinformatics scientist usually writes Python or R scripts to analyze and visualize data. The engineer role emerged as data volumes exploded—it’s essentially software and data engineering, but with an understanding of biological data characteristics.
Biological data looks very different from tech company data. Specialized platforms emerged for handling it. Engineers build data pipelines and infrastructure, often doing initial analyses. Once pipelines mature, scientists can run them independently. But engineers must still understand how the experimental data was generated—different data types require different algorithms. At GRAIL, for instance, aligning DNA sequences and de-duplicating data required custom algorithms embedded into pipelines for scientists to use.
Right now, our main focus is on the scientist side. Pipelines are mostly deterministic—once set, they should run stably. While AI can help write pipelines, you don’t need AI in the loop every time they run. Scientists, however, typically load data into Jupyter Notebooks, interactively coding based on results, with each step shaping the next. That reasoning-heavy workflow is where AI Agents can shine.
Both roles are hard to fill. I’ve helped recruit for both across companies, and it often takes months to find qualified candidates—not because no one applies, but because the roles aren’t standardized like in big tech. At Google or Microsoft, software engineering roles have similar requirements. In biotech, companies want candidates with domain-specific knowledge: an immunology company and an infectious disease company may need different expertise. That applies to engineers and scientists alike.
These roles also demand skills in biology, CS, and statistics. If someone is strong in all three, they could earn more at a tech company, which complicates hiring. Salaries in Silicon Valley are comparable to tech, but biotech equity is often less valuable. And since the field is young, there simply aren’t many people with years of experience. In practice, hiring is slow.
Quinn Leng: Exactly. And compensation in these companies is heavily weighted toward equity.
ZP: From a data volume perspective, how does biotech compare with big tech?
Ashton Teng: On a per-dataset basis, biotech data is larger, but there’s no “one billion users” concept. So total volume is hard to compare directly.
Quinn Leng: It’s really apples to oranges. Data types are entirely different. A single biological experiment can generate gigabytes of data from just one sample. You’d never get gigabytes from a single user in tech.
02. Rebuilding the Research Workflow: How AI Agents Solve the “Last Mile” in Life Sciences
ZP: What core problem did you set out to solve when you founded Kepler?
Ashton Teng: Kepler started with a focus on biological data analysis, but its vision has always been broader. At its heart, it’s an AI Agent—flexible enough to handle a wide range of scientific tasks, especially those involving data and information. More precisely, it’s an Enterprise AI Agent for Life Science Research.
Here’s what that means in practice: before experiments, Kepler can search the literature and help generate new hypotheses. During experiments, it can plug into data pipelines and run processing workflows. Afterward, it can analyze results in the context of both experimental metadata and biological data—then connect those findings back to prior knowledge within the organization. From there, it can assist with drawing conclusions, drafting reports, and even suggesting the next research questions to pursue. In other words, Kepler isn’t just a data analysis tool—it functions much more like an end-to-end scientist.
Before AI Agents, nearly every step of this workflow was manual. Data pipelines could run automatically, but scientists still had to gather information through search engines, sift through PDFs and slide decks, and piece together how past teams had solved related problems. Bioinformaticians also had to spend significant time going back and forth with experimental scientists just to clarify design and context. In reality, most scientists were splitting their time in half—only about 50% went into actual lab work, while the other 50% was spent on information gathering and handling.
Our vision is that, aside from the hands-on lab experiments themselves, all research tasks that involve data or information should be augmented by AI. And Kepler doesn’t just replicate existing workflows—it goes further. Because our system can batch questions and interact with data at scale, it can explore hundreds of lines of inquiry at once, dramatically accelerating discovery and broadening the scope of what can be uncovered. It saves time, yes, but more importantly, it expands the horizons of scientific possibility.
In terms of delivery, our AI Agent is designed for direct use by researchers. Users can pose a research question or give the Agent instructions, and it will interact with them, create a plan, and carry it out. At the early stage, we help enterprise clients connect the Agent to their internal databases—because access to in-house information is crucial—but we don’t take over the actual research itself. That remains in the hands of scientists; Kepler simply amplifies what they can achieve.
Quinn Leng: To add to that, what we’re tackling is one of the most complex challenges in the industry. Very few intelligent systems today can actually handle hundreds of gigabytes of messy, multi-modal data. These datasets vary enormously in scale, precision, and structure, making system architecture design extremely difficult. On top of that, we need to invent entirely new modes of interaction so scientists can actually use these systems efficiently. These are very real, very technical problems.
ZP: From a technical perspective, what are the core challenges you face?
Quinn Leng: There are quite a few. The first is alignment and integration—how do we get AI to truly understand domain-specific needs? Take ChatGPT as an example: unless it’s connected to the right specialized tools, even with MCP bridges, the results fall far short. In life sciences, the tools are nothing like traditional ones. The data is multi-modal, highly complex, and the workflows often require domain-specific feedback loops for training before the AI can really “understand” what the data means.
The second is verifiability—how do we validate that a result is correct? In science, producing a result isn’t the hard part—you can always run more experiments. The challenge is making sure those results are grounded and reliable. One of the common criticisms of current AI products is that they “hallucinate,” because they lack robust verification. That’s why we’ve seen the progression from ChatGPT to Perplexity to Deep Research. But in science, we need to go deeper still. It’s not enough to search the web for papers—you might need to actually load experimental data, run analyses, and simulate outcomes. For instance: how does a particular type of genetic data interact with a drug compound? Can the Agent pull data from two separate databases, simulate the interaction, and then report that “7.5% effect size” as the outcome of an actual computational experiment—not just a claim scraped from the web? For scientists, this level of traceability is critical. They don’t just want conclusions—they need results that are connected directly to facts.
Ashton Teng: These tasks do involve coding, but they’re far harder to validate than typical AI programming. With AI coding, you can submit a PR, write a test, and instantly check if it works. In science, the “test” is much longer and more nuanced. You can’t easily validate whether a statistical method is appropriate or whether a grouping definition makes sense just by running a script—it requires deep domain expertise. That’s why AI programming advanced faster than AI for scientific data analysis. For us, the challenge is even greater because our end-users are often experimental scientists rather than trained bioinformaticians. That means we need to design interfaces where the Agent’s reasoning process is transparent, so scientists can see how conclusions are reached.
Ashton Teng: These kinds of tasks do involve coding, but they’re much harder to validate than typical AI programming. In AI programming, you can submit a pull request, write a test, and a human can immediately check whether the function works as intended. The validation cycle is short. In science, the validation process is very different and much longer—that’s one reason why AI coding took off earlier.
With data analysis, it’s not so simple. You can’t just run a test to know if a statistical method is appropriate or whether the way you’ve defined groups makes sense. The level of domain expertise required is much higher. On top of that, many of our users are experimental scientists rather than trained bioinformaticians, which means we have to design very clear interfaces where the Agent’s reasoning process is transparent and traceable.
Quinn Leng: Exactly—and that’s not just an engineering hurdle, it’s also a completely new frontier in human-Agent interaction. No one has really built a product for “scientist–AI Agent collaboration” before. For example: how precise should citations be? Deep Research can point to a webpage, but in science we might need to cite a specific experiment, or even a single row in a database. How do we design that workflow? Which steps can the Agent carry out autonomously, and which require explicit confirmation from the scientist? These are all new patterns of interaction, and they require us to rethink the entire process.
ZP: So how are you designing Kepler’s user interaction model?
Quinn Leng: Our approach is to integrate with as much of the scientists’ existing ecosystem as possible—their Jupyter notebooks, structured and unstructured databases, even obscure file formats, along with upstream lab record systems like Electronic Lab Notebooks. But once you connect to all of these data and tools, the bigger challenge becomes: how do you manage them so the Agent can actually find and use what’s relevant? That’s where we build a knowledge graph to organize and navigate the context. It’s almost like creating an onboarding manual for a new team member—helping the Agent ramp up quickly so it can operate across the entire research environment.
ZP: You landed your first enterprise customer in the very first week after founding Kepler. Can you share that story?
Ashton Teng: We started Kepler in early May, and within the first week we signed our first customer. It came through a personal introduction—biotech is a relationship-driven field, and a lot of the companies are clustered here in Silicon Valley. At a private gathering hosted by a former colleague from one of my previous biotech companies, I met the CSO of Tahoe Therapeutics. We started talking about what we were building, and he immediately said, “This is exactly what we’ve been looking for.”
We later learned that Tahoe had already been planning for a system that could interact with data through natural language, but since they weren’t a software-first company, building it in-house was too difficult. They had considered outsourcing, but the results weren’t good enough. The timing worked out perfectly—we had the product expertise, and they had the data. They became our first design partner and early customer, helping us iterate on the initial product. We’re really grateful for that. Even though Tahoe is still a startup, they’ve built significant influence in the AI + Bio space. They had just raised $30 million to develop foundation models for biology. That partnership was a bit serendipitous, but it also validated the demand we were seeing across the industry.
ZP: What does a typical target customer look like for Kepler?
Ashton Teng: Our customers fall into different categories. As with any new technology, there are early adopters and late adopters. The pain points are broadly similar, but some companies are more conservative. After our launch, the ones who reached out proactively were innovative biotech firms, especially those already experimenting with AI—many of them working on foundation models in biology. They’re not strictly AI-native, but being in Silicon Valley makes them more open to trying new AI software. They also tend to have large datasets, so the pain points are sharper.
That’s one segment. Another important group is academic labs. Labs usually don’t have the budget that enterprises do, but their challenges are very real. Many biologists joining labs still need to teach themselves programming to analyze data, because unlike companies, they don’t have dedicated bioinformatics teams. We want to support these labs as well, so we collaborate with academic researchers in parallel with our enterprise work.
ZP: What about large pharmaceutical companies? Given their scale and well-established teams, are they also your target customers?
Ashton Teng: Yes, in fact we’re already working with one of the world’s top 20 pharmaceutical companies. They have large internal AI teams and have even tried to build their own ChatGPT-like tools for data analysis. I don’t know all their internal details, but what’s interesting is they reached out to us directly after seeing the news of our launch—they actually contacted us through the investor information on our website.
Competition in pharma is fierce, and AI transformation has become a core performance metric. While these companies can hire talent, they’re not AI-native. Their internal tools are often limited in speed and generalizability. They’re fine for small, isolated tasks, but not reliable or extensible enough to serve as enterprise-wide solutions. That’s where we see the opportunity: pharma is realizing that in some areas, it makes more sense to buy rather than build. Each company weighs “build vs. buy” differently, but it’s clear that many are now actively looking for external AI solutions.
Quinn Leng: I’ve seen this dynamic many times. Pharma usually faces at least two layers of gap with cutting-edge AI: first, their software teams often lack the same level of technical expertise as Silicon Valley companies. Second, even their software engineers don’t have deep AI expertise. So you often see them attend a few AI workshops, believe they can build solutions internally, then fall behind within months as the tech evolves. Eventually, they end up procuring external solutions. That’s exactly what happened after ChatGPT launched—many tried to build their own, but as complexity increased, they switched to buying tools. The same is happening now with literature management systems, experimental platforms, and beyond.
For us, this creates an opportunity. Agent systems like the ones we’re building need to execute workflows: run analyses, access sensitive datasets, write code, and orchestrate pipelines. Done right, it’s a huge productivity boost. Done wrong, it could introduce major security risks—like giving an internal agent the potential to act like a rogue hacker. So building secure, compliant agents is not only an engineering challenge, it’s an industry-wide necessity.
ZP: Right now you don’t seem to have many direct competitors. Who do you see as your likely competitors in the future?
Ashton Teng: A number of startups are emerging in this space, and there will certainly be more. But what really matters is execution. Our strength is our enterprise software background—we know how to deploy into real workflows and move quickly. Also, our scope is different from others.
That said, the competitor I watch most closely is actually Palantir. Their model is “forward deployment”—embedding engineers directly inside enterprises to customize solutions. They’ve already secured contracts with two major pharmaceutical companies, mainly in manufacturing and data management. That makes them worth paying attention to. But their business model limits scale: it’s slow to expand because it depends on human deployments. They’ve been around for years and only entered two pharma clients. Plus, their scope isn’t exactly the same as ours.
At the moment, we’re not too concerned about companies like OpenAI or Anthropic, since their focus is on building general-purpose tools, while we’re optimizing specifically for the unique needs of the life sciences. These general providers face what we call the “last mile” problem—they don’t go deep enough into enterprises to integrate with actual workflows.
Palantir, on the other hand, has already broken into two pharmaceutical companies. While they may currently focus more on manufacturing or data management, they do have the capability to deploy engineers directly on-site to build tailored solutions for clients. Among the different types of potential competitors, Palantir is the one we pay the most attention to. That said, their business model naturally limits how fast they can scale—the company has been around for many years and still only serves two pharma clients, and their scope doesn’t fully overlap with ours.
ZP: When customers evaluate software providers, what are their top criteria?
Ashton Teng: Reputation and credibility come first. That’s why we’ve always positioned ourselves as an enterprise-grade solution. As a startup, you need to win trust. Biotech is a relationship-driven ecosystem—it’s not always about who has the most advanced tech, sometimes your track record or partnerships matter more. Traditionally, big pharma prefers working with established software vendors, while biotech startups are more flexible.
But here’s the shift: in AI, the old guard software providers can’t keep up with the pace of innovation. They lack strong AI products. This has opened a rare window of opportunity—pharma is now willing to work with early-stage AI startups. That was almost unheard of before. The norm used to be: start with smaller biotech clients, prove yourself, then gradually work your way up to pharma. Today, pharma is actively evaluating new AI startups from the start.
ZP: Today you’re focused on life sciences. What’s the roadmap for expanding beyond?
Ashton Teng: Our long-term vision is to become the “central nervous system” of every research organization. While we’re currently focused on the life sciences—particularly AI agents designed for research tasks—our technology can naturally extend into other scientific domains such as materials science, climate science, and agriculture, all of which share similar R&D needs.
Our core belief is this: although there are enterprise-level AI agents built for IT automation, HR automation, and related areas, the mission and daily workflows of research organizations are fundamentally different from those of product-oriented companies. That’s why an enterprise AI agent purpose-built for research tasks represents a unique positioning—one that can scale across scientific fields well beyond biology.
ZP: Some startups are focusing on the experimental side, with software or hardware that automates lab work. You’re focused on everything around the experiment—data and knowledge. Do you think these two worlds will converge?
Ashton Teng: I see them as complementary. One side is focused on knowledge and intelligence, the other on automation. There’s huge potential to integrate the two, through APIs or deeper partnerships. Of course, some well-funded companies are going full-stack—building their own labs and pursuing “lab-in-the-loop” models where they develop drugs end-to-end rather than selling software. But not every company can or should take that path. Most organizations will still need external AI tools. It’s like coding assistants—once a team adopts one, their productivity jumps, and that advantage drives adoption across the industry.
ZP: Looking ahead, what are the top three priorities for Kepler over the next year?
Ashton Teng: There’s been a lot of attention on this question—whether from the broader AI-for-science community or other teams. It’s not just about efficiency gains; the field itself is inherently exciting, and far more compelling for talent than applications of AI in traditional sectors like insurance. The concentration of talent in AI for science is rising rapidly, which gives us strong confidence in the future.
While competition is intense, I don’t believe any single company will monopolize the market. Scientific research is vast and unlike areas such as sales automation, which have a clear ceiling. Scientific exploration has no boundaries, and AI in this domain has virtually limitless potential. There’s plenty of room for multiple companies to thrive side by side.
Three things we will focus on in the next year: First, cementing our leadership in enterprise AI Agents for life science research. That means hiring the right people, co-developing with our core customers, and building credibility.
Second, deeply integrating into customer workflows. We don’t just want to analyze data—we want to become their “system of record,” where data is stored, shared, and continuously enriched. That creates real stickiness.
Third, expanding our product capabilities. We want to continuously increase the value of the platform so that once customers adopt it, it becomes very hard to switch away.
Beyond that, our biggest focus is talent. We want to attract people who are curious, motivated, and excited by the intersection of AI and science. Our pitch is simple: First, we’re an AI-native company, which means we’re open to experimenting with any new technology that could be useful. Second, we care not only about AI itself but also about process optimization—we see the company as a living organism that needs to evolve and iterate quickly. Our hope is to attract people who are deeply curious about scientific work and eager to explore and discover, and bring them into this fast-growing AI data startup.
04. Quick Q&A
ZP: Let’s switch gears with a few lighter questions to get to know Ashton and Quinn outside of work. First, could you share your zodiac signs or MBTI personality types?
Ashton Teng: I’m a Leo, and my MBTI is INTJ.
Quinn Leng: I’m a Gemini, INFJ.
ZP: What hobbies do you have outside of work?
Quinn Leng: I love cooking, especially complex dishes. Lately I’ve gotten into skateboarding—I even commute by board now. I also enjoy skiing and diving.
Ashton Teng: Quinn really is an incredible cook. During the first two weeks of starting the company, I ate at his place almost every day, and he always managed to whip up these beautifully crafted meals. He cooks under pressure; I eat under pressure. Stress makes me eat a lot. Eating is definitely my favorite pastime, so I try to balance it with exercise, like going to the gym. We both enjoy skiing and diving. I used to read a lot, but now I mainly listen to books on Audible.
ZP: We also invested in a more AI-native audiobook product, though it’s still in an experimental phase.
Ashton Teng: I’ve been searching for the ideal “real-time reading” product—something that generates content dynamically based on your questions and interests, gradually building a personal knowledge graph that reflects your cognitive boundaries. Imagine every morning, during a spare 20 minutes, being served content that’s just challenging enough to expand your thinking—neither too simple nor too overwhelming. Most books are either repetitive or overly dense. Personalizing content to match someone’s exact level of understanding is a fascinating direction. For nonfiction, you could even use signals like fast-forwarding or replaying to adjust difficulty. But of course, people also listen to audiobooks for relaxation, not just to learn.
ZP: Entrepreneurs often end up designing products for hyper-disciplined users—over-optimizing for efficiency and data tracking. But that’s really a niche audience.
Quinn Leng: Right, that tends to lead to overfitting.
ZP: What’s the book or person that has influenced you most?
Quinn Leng: Sapiens gave me a lot of perspective on human history through an information lens, but the book that shaped me most was Jun Wu’s The Wave Crest. It traces the history of Silicon Valley and helped answer the two questions I obsessed over in college: how to create cutting-edge technology, and how to make sure that technology actually reaches people. IBM built the first computers, but it was Microsoft and Windows that made them ubiquitous. Apple didn’t invent the mouse or the touchscreen, but it was the first to bring them to the masses. That book taught me the importance of commercialization, and the cycles of rise and fall in tech companies.
Ashton Teng: I mostly keep up with real-time information through tech podcasts, but in terms of books, I also enjoyed Sapiens. The book that influenced me most, though, was Guns, Germs, and Steel. Even though its geographic determinism has limitations, it opened my mind to thinking about large-scale social systems. Later I read Why Nations Fail, which takes an institutional perspective. What fascinates me is how human social organizations and systems come into being. These structures are what free us to do science and build startups instead of worrying about basic survival. Civilization itself is an incredible feat.
ZP: What AI products do you use most?
Quinn Leng: We use Devin and Claude Code the most. They’re not perfect, but they’re the AI programming tools we rely on every day. Honestly, I haven’t seen a single AI product yet that feels fully convincing. Devin is decent as an AI-native tool, but nowhere near perfect. I expect we’ll see much stronger products emerge in the next year or two.
Ashton Teng: I don’t form emotional attachments to AI products. I don’t chat with AI for fun. For me it’s strictly a tool. That’s why our own product doesn’t aim to provide “emotional value.”
ZP: Why Devin over Cursor or others?
Quinn Leng: Cursor is more like Copilot—an assistant. Devin is closer to autonomous programming. We designed our company so that onboarding a new employee is the same as onboarding a new agent—they need to understand the entire context, from development to testing. Devin is the best at that right now.
Ashton Teng: Cursor can’t absorb a company’s full context. You have to re-explain things every time. Devin can navigate the entire codebase and complete tasks independently. That’s exactly the model we borrowed for our own product design. Copilot-style assistants only work for bioinformatics experts. They don’t help other scientists analyze data.
ZP: What you describe—an AI that carries historical data and workplace context—doesn’t yet exist in writing or research tools.
Ashton Teng: That’s a huge gap we’ve felt since starting the company. Coding efficiency has improved a lot, but company operations haven’t. There should be a tool that generates tweets for me based on the company’s strategy, or writes tailored copy for investors, customers, or employees. Instead, I have to start from scratch each time.
I also believe work and personal life should be served by different AIs. Work involves complex relationships that a “general assistant” can’t handle well. Ideally, I’d have a dedicated work assistant and a dedicated personal assistant, each with full context.
ZP: For me, Gemini is still the AI I use most often. Half a year ago, AI couldn’t even summarize meeting notes properly. Now Gemini’s output is 80–90% as good as a human.
Ashton Teng: That’s the challenge for startups—big platforms have the natural advantage of being the system of record. Even if Notion is better in some ways, we end up using Google Docs because everyone around us is on Google Workspace. In research, there’s still no universal standard for data analysis and sharing. That lack of standardization actually creates opportunities.
ZP: You must listen to a lot of podcasts. Any recommendations?
Ashton Teng: Acquired. It’s a business history podcast with one in-depth episode a month. The content is extremely detailed.
The VC world is also becoming more competitive. Building a personal brand matters. Jack Altman recently started Uncapped with Jack Altman. For VCs, bringing visibility to portfolio companies is incredibly valuable, and a podcast can be a powerful way to do that.
Quinn Leng: I’d recommend No Priors, hosted by Sarah Guo. She’s an investor, but also a deep thinker, and her guests include founders and customers with really sharp insights. Her curiosity and energy make it a great listen. Many companies even talk to her before launching products.
Y Combinator also does this well. Their YouTube channel has both educational and interview content, and every episode now racks up millions of views.
Disclaimer
Please note that the content of this interview has been edited and approved by Ashton Teng and Quinn Leng. It reflects the personal views of the interviewees. We encourage readers to engage by leaving comments and sharing their thoughts on this interview. For more information about Kepler AI, please explore the official website: https://www.getkepler.ai/.
Z Potentials will continue to feature interviews with entrepreneurs in fields such as artificial intelligence, robotics, and globalization. We warmly invite those of you who are hopeful for the future to join our community to share, learn, and grow with us.
Image source: Ashton Teng, Quinn Leng, and Kepler AI
Thanks so much Z Potentials for this opportunity to share our story!